
Wie erfolgreiche Organisationen Engpässe finden und echte Delivery Performance herstellen
In den ersten beiden Teilen dieser Serie haben wir gesehen, warum Delivery Performance nicht davon abhängt, wie fleißig Teams arbeiten oder welche Methoden im Einsatz sind, sondern davon, wie Arbeit wirklich durch den Wertstrom fließt.
Wir haben uns angeschaut, warum „mehr machen“ so oft zu „weniger liefern“ führt und dass Wertströme in vielen Organisationen völlig unsichtbar sind, obwohl genau sie darüber entscheiden, wie schnell, wie stabil und wie vorhersehbar ein Unternehmen Wert erzeugen kann.
Heute gehen wir in die Praxis:
Wie optimiert man Flow, wenn der Wertstrom endlich sichtbar ist?
Und warum ist genau das der Punkt, an dem erfolgreiche Organisationen das Spiel gewinnen und andere stecken bleiben?
1. Das große Missverständnis: Warum Optimierung fast überall beginnt, nur nicht dort, wo sie wirken würde
Wenn wir in eine Organisation kommen, passiert fast immer das Gleiche:
Bevor überhaupt jemand weiß, wo Arbeit wirklich fließt, wird schon optimiert.
Da wird an Meetings geschraubt, Prozesse werden verschlankt, neue Tools eingeführt, OKRs neu sortiert, Teams reorganisiert und Frameworks „ausgerollt“.
Die „Performance der Teams wird optimiert“ heißt es dann so schön. Kernaufgabe der Coaches.
Und trotzdem bleibt die Delivery Performance, wie sie war: langsam, unzuverlässig, überlastet.
In einem bekannten deutschen Automotive Unternehmen, das wir begleitet haben, waren beispielsweise die IT-Teams zu 90–100 % ausgelastet, teilweise sogar über die 100% durch Taskforces und Incident management. Die Geschäftsführung war stolz auf die beeindruckende „Resource Utilization“ und optimierte auch in der Form: Wenn Mitarbeiter „nicht vollständig ausgelastet“ waren, bekamen diese Sonderaufgaben wie interne Verwaltungsaufgaben oder Dokumentationen aufhübschen.
Trotzdem warteten Features teilweise 80 Tage auf ein Review, bevor auch nur eine Zeile Code produktiv ging.
Lead‑Times von über vier Monaten waren normal.
Der Grund ist simpel und brutal zugleich:
Flow bricht nie überall gleichzeitig. Flow bricht immer am Engpass.
Und wenn man überall optimiert außer dort – dann passiert exakt gar nichts.
SAFe (auch wenn wir das Framework durchaus differenziert sehen) bringt dieses Prinzip handfest auf den Punkt:
Flow ist die „schnelle, lineare und ununterbrochene Bewegung von Arbeit durch den Wertstrom“.
Und wenn diese Bewegung ins Stocken gerät, dann nicht, weil Teams zu wenig geben, sondern weil die Arbeit wartet, nicht weil sie langsam bearbeitet wird.
Ein weiteres Beispiel für eine vermeintliche Performanceoptimierung und dem Ziel möglichst alle immer auszulasten findet ihr hier.
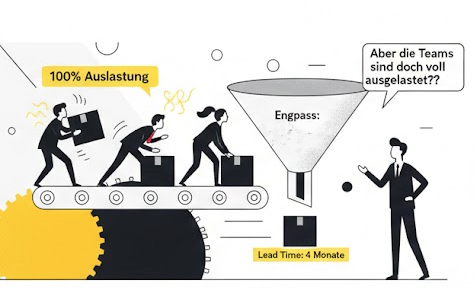
2. Der Engpass bestimmt die Delivery Performance. Immer.
Einer der wichtigsten Sätze in der gesamten Flow‑Logik lautet:
Der Engpass steuert den Wertstrom. Nicht die Teams.
Wir sind oft überrascht, wie tief dieses Missverständnis sitzt.
In vielen Organisationen versuchen Teams, „ihre eigene Geschwindigkeit“ zu erhöhen. Sie verbessern Prozesse, sie automatisieren Dinge, sie tun alles, um schneller zu werden.
Doch all das ist bedeutungslos, wenn die limitierende Stelle woanders liegt.
Wenn der Engpass z. B. nicht im Development sitzt, sondern in Requirements, QA, Security, Architektur oder im Deployment, dann verbessert jede lokale Optimierung zwar die Auslastung der Teams, aber nicht die Delivery Performance.
Und aus unserer Erfahrung in Deutschland: leider ist eines der größten Bottlenecks der Betriebsrat. Zeitlich nicht planbar und und unvorhersehbar was als Feedback kommt.
Das zeigt auch eindrucksvoll die Flow Efficiency:
In einer echten Wertstromanalyse betrug die Flow‑Effizienz gerade einmal 5 %.
Das bedeutet: 95 % der Zeit lag die Arbeit einfach herum und wartete auf den nächsten Schritt.
Wir sehen solche Zahlen häufig.
Die Organisation denkt, es sei ein Kapazitätsproblem.
In Wahrheit ist es fast immer ein Flow‑Problem.
3. Die fünf Engpass-Typen, die in fast jeder Organisation auftauchen
Wir haben in den letzten Jahren zahlreiche Wertströme analysiert — kleine Teams, skalierte Produktorganisationen, Mittelstand, Konzerne.
Faszinierenderweise tauchen dieselben Engpassmuster immer wieder auf, egal welche Branche oder welchen Reifegrad eine Organisation hat.
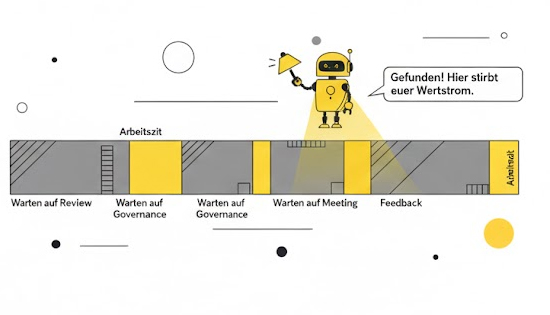
3.1 Der unsichtbare Engpass: Warten statt Arbeiten
In vielen Systemen wird kaum gearbeitet, aber sehr viel gewartet.
Eine Aufgabe, die in 2 Stunden erledigt wäre, liegt fünf Tage in einer Queue, wartet auf Feedback, auf ein Meeting, auf einen Review‑Slot oder auf eine Person, die gerade zu 140 % eingebunden ist.
Um die Wartezeit zu überbrücken wird daher weitere Arbeit in den Teams gestartet und dann wieder weitere. Multitasking lässt grüßen.
Diese Wartezeiten sind der echte Kostenfaktor.
Und sie sind der stärkste Bremsklotz für Delivery Performance.
Mik Kerstens Flow Framework nennt das „Flow Efficiency“ und fast alles, was Unternehmen für langsame Arbeit halten, ist in Wirklichkeit langsames Warten.
3.2 Rollen-Engpässe: Eine Person hält fünf Teams auf
Ein klassisches Muster was wir in einem deutschen größeren Mittelständler erleben durften:
- Ein PO priorisiert für mehrere Teams
- Ein Architekt muss jede Entscheidung absegnen
- Eine QA prüft alle Releases
- Ein Security-Team macht Compliance nur alle zwei Wochen
Diese Personen sind nicht das Problem.
Sie sind nur der Engpass.
Und wenn der Engpass überlastet ist, bricht der gesamte Wertstrom.
Ein Beispiel: In dem Setup wurden neue Tools für die Mitarbeiter entwickelt, verprobt und ausgerollt. Die Teams waren gut unterwegs und haben Ihre Themen in 3 Monats-Iterationen geplant und abgearbeitet. Jedoch gab es ein sichtbares Muster, welches nach Auswerten der Flow Zahlen sichrbar wurde. Die effektive Arbeitszeit war nicht das Problem, alle internen Arbeiten wurden innerhalb des geplanten Zeitraums fertig. Aber als letzte Flow-step musste das Thema erst durch den Betriebsrat und auch durch die Security. Diese Schritte haben zum Stillstand geführt, da nicht vorhersehbar war was genau als Feedback aus den Bereichen zurückkommt, wann genau das Feedback kommt und welche Auswirkungen es für den Abschluss hat.
Leider wurde nur am Team optimiert, wobei eine Lösung gewesen wäre:
Integration der Security und Betriebsrat in den Entwicklungsprozess und als Teilnehmer der Crossfunktionalen Teams.
3.3 Handoffs und Meetings: Optimiert die Ursache, nicht die Symptome
Viele Organisationen versuchen, Meetings zu reduzieren.
Erfolgreiche Organisationen optimieren die Notwendigkeit von Meetings.
Wenn Arbeit ständig über Abteilungen, Rollen, Teams oder Tools springt, entsteht:
- Abstimmungsbedarf
- Unsicherheit
- Rework
- Statusmeetings
- Mehrfachklärung
SAFe beschreibt das als „Minimize Handoffs and Dependencies“ und zwar zu Recht.
Übergaben sind Flow-Killer Nummer eins.
Was dabei hilft ist ein Denken wie in der Software Entwicklung: Denken in automatisierte Schnittstellen. Übergaben müssen nicht immer in Meetings und Face-to-Face stattfinden, sondern in Interaktionen über automatisierte Chats oder über intelligente AI Agents.
3.4 Demand-Chaos: Zu viel gleichzeitig, zu wenig fertig
In erstaunlich vielen Organisationen ist der eigentliche Engpass nicht im Delivery‑Prozess, sondern davor: bei der Priorisierung.
Wenn alles wichtig ist, ist nichts wichtig.
Teams starten zu viel, um ja nichts zu blockieren und werden dadurch selbst zum Blocker.
Erst, wenn die Arbeit in kleineren, kontrollierten Teilmengen fließt („Work in Smaller Batches“), steigt die Vorhersagbarkeit.
3.5 Der Prozess-Engpass: Wenn Technik den Wertstrom drosselt
Viele Wertströme werden durch technische Infrastruktur oder Governance gebremst:
- monatliche Releases
- manuelle Deployments
- komplexe Compliance‑Prüfungen
- fehlende Testautomatisierung
- zentralisierte Architekturentscheidungen
Das ist oft der Engpass, den niemand sieht, weil er „schon immer so war“.
4. Wie man Engpässe sichtbar macht – und warum AI dabei ein Gamechanger wird
Die gute Nachricht:
Engpässe sind selten subtil.
Sie sind nur schwer zu sehen, wenn man die falschen Daten anschaut.
Diese Flow-Metriken geben eine solide Grundlage:
- Flow Time
- Flow Load
- Flow Efficiency
- Flow Distribution
- Flow Velocity
Doch in den letzten zwei Jahren ist etwas Spannenderes passiert:
AI beginnt, Flow‑Probleme automatisch zu erkennen
Die Recherche zeigt eindrucksvoll:
- Tools wie „Delivery Flow for Jira“ analysieren automatisch Bottlenecks und Wartezeiten
- Der „Clovity AI Copilot“ findet Flow‑Störungen, bevor Teams sie sehen
- Atlassians Rovo Dev identifiziert Arbeitslast, technische Schulden und Bottlenecks kontextbezogen im Wertstrom
- Tools wie Axify verbinden Code‑Metriken mit End‑to‑End Delivery Performance und warnen vor lokalem Optimieren
Hinzu kommt:
Auch ohne konkrete Tools könnt ihr AI als Sparring Partner nutzen und zusammen in CI/CD frühzeitig Pipeline‑Bottlenecks , Wartezeiten, teure Abhängigkeiten und Flaky Tests erkennen.
Das verändert alles.
Zum ersten Mal ist es möglich, Flow‑Diagnose in Echtzeit zu automatisieren statt einmal im Quartal bei einem Value‑Stream-Mapping-Workshop.
5. Was erfolgreiche Organisationen heute schon tun
In allen Projekten, die wir begleiten, sehen wir dasselbe Muster erfolgreicher Flow‑Optimierung:
- Sie optimieren das System um den Engpass und nicht um die Teams
- Sie reduzieren parallele Arbeit drastisch
- Sie bekämpfen Wartezeit, nicht Arbeitszeit
- Sie bauen Führung um Flow, nicht um Tasks
- Sie nutzen AI nicht zum kosten sparen, sondern zum Flow Optimieren
SAFe formuliert es so:
„Busy leaders struggle to spend time in the zone… and create decision bottlenecks.“
7. Fazit
Flow optimieren heißt nicht:
- schneller arbeiten
- härter arbeiten
- mehr arbeiten
Flow optimieren heißt:
- die limitierende Stelle zu erkennen
- Wartezeiten sichtbar zu machen
- Arbeit zu entlasten statt zu beschleunigen
- die Organisation um den Engpass herum neu zu organisieren
- AI‑gestützt zu verstehen, wie der Wertstrom sich wirklich verhält
Delivery Performance wächst nicht aus Fleiß.
Sie wächst aus Fluss.
8. Ausblick auf Teil 4
Im nächsten Teil geht es darum, wie man die richtigen Methoden — Kanban, Flight Levels, TOC, Flow Analytics, Lean Portfolios — einsetzt, ohne in Framework‑Theater zu verfallen.